
무신사 블프 이벤트 상품 동시성 문제 (2)
이전 글에서는 이벤트 상품 동시성 처리를 동기적으로 하였다.
이번 글에서는 비동기적으로 처리하는 방법에 대해서 알아보겠다.
우선 동기적으로 처리하면 Lock을 사용하기 때문에 다른 스레드들이 Blocking 되기 때문에 TPS 감소 및 성능 저하가 발생한다.
따라서 Message Queue를 이용하여 비동기 처리를 해보려고 한다.
- Redis pub/sub
- 휘발성 특징 때문에 메시지를 전송하고 나면 데이터가 사라짐. 따라서 실제로 이벤트 상품 요청을 보냈는지 검증하기 힘듬
- 메세지의 신뢰성이나 지속성이 중요하지 않은 서비스에 적합하고 대규모 처리가 어려움
- Kafka
- 디스크에 저장되서 데이터 유실이 적고, 속도측면에서도 빠르고 대규모 분산 시스템에 적합함. 하지만 설정과 관리가 복잡하며, 초기 구성과 유지보수에 대한 학습 비용이 높다.
- RabbitMQ
- 디스크에 저장되서 데이터 유실이 적지만 메세지 처리 속도는 Redis 보다 느림.
- Message Queue에 있는 모든 메세지가 consumer에게 전달되는게 보장됨
위의 특징들을 고려하여 RabbitMQ로 선정하였다.
RabbitMQ

RabbitMQ는 Publisher와 Consumer가 있는데, 쉽게 생각하면 Publisher를 통해 Queue에 메세지를 적재하고, Consumer가 Queue를 확인하여 메세지를 소비한다.
이 아이디어를 이벤트 상품 재고 시스템에 적용해 보면 이벤트 상품 request를 Message Queue에 적재한다. Message Queue는 FIFO 방식으로 동작하므로 요청 순서대로 메시지를 처리하게 되어 선착순으로 이벤트 상품을 처리할 수 있다.
@Configuration
public class RabbitMqConfig {
@Value("${spring.rabbitmq.host}")
private String rabbitmqHost;
@Value("${spring.rabbitmq.port}")
private int rabbitmqPort;
@Value("${spring.rabbitmq.username}")
private String rabbitmqUsername;
@Value("${spring.rabbitmq.password}")
private String rabbitmqPassword;
@Value("${rabbitmq.queue.name}")
private String queueName;
@Value("${rabbitmq.exchange.name}")
private String exchangeName;
@Value("${rabbitmq.routing.key}")
private String routingKey;
@Bean
public Queue queue() {
return new Queue(queueName);
}
@Bean
public DirectExchange directExchange() {
return new DirectExchange(exchangeName);
}
@Bean
public Binding binding(DirectExchange directExchange, Queue queue) {
return BindingBuilder.bind(queue).to(directExchange).with(routingKey);
}
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
connectionFactory.setHost(rabbitmqHost);
connectionFactory.setPort(rabbitmqPort);
connectionFactory.setUsername(rabbitmqUsername);
connectionFactory.setPassword(rabbitmqPassword);
return connectionFactory;
}
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory, MessageConverter messageConverter) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setMessageConverter(messageConverter);
return rabbitTemplate;
}
@Bean
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}
}
우선 RabbitMQ를 세팅해 준다. DirectExchange 방식을 사용하였고, Single Queue를 사용하였다. (선착순 이벤트를 위해)
Exchange Type은 크게 4가지가 있다.
- Direct Exchange: 라우팅 키와 일치하는 큐에 메시지를 보냄
- Fanout Exchange: 라우팅 키를 무시하고 바인딩된 모든 큐에 메세지를 보냄
- Topic Exchange: 라우팅 키에 와일드카드 문법을 사용하여 큐에 메시지를 보냄
- Header Exchange: 라우팅 키를 사용하지 않고, 헤더의 속성을 보고 메세지를 보냄
Single Queue를 사용하기 때문에 Direct Exchange 방식을 사용하였다.
이제 이벤트 상품을 처리하는 로직을 보자.
public void processEventProduct(OrderDto.EventOrderRequest req, Long eventProductId, LocalDateTime currentTime) {
checkValidEventDateAndTime(req.getEventId(), currentTime);
EventProductRedis eventProduct = eventProductCacheService.getEventProduct(eventProductId);
checkValidEventProductRequest(eventProduct, req.getMemberId());
producer.producer(new EventProductMessageDto(req.getMemberId(), eventProductId));
}
위 메서드를 보면 우선 validation 체크를 해주고 나서 메세지를 생성하는 것을 볼 수 있다.
이때 이벤트 상품의 재고는 한정된 수량이므로 이를 체크해 주기 위해서 Redis를 사용하였다.
private void checkValidEventProductRequest(EventProductRedis eventProduct, Long memberId) {
int q = eventProduct.eventQuantity();
String key = getEventProductRequestKey(eventProduct.eventProductId());
Long count = redisRepository.increment(key);
if (q < count) {
throw new EventProductQuantityException("이벤트 상품 재고가 소진되었습니다.");
}
}
매 요청마다 redisTemplate의 increment를 통해 값을 체크해 주었다. increment는 함수는 atomic을 보장하므로 race condition을 방지할 수 있다.
@RabbitListener(queues = "${rabbitmq.queue.name}")
public void consumeEventProductMessage(EventProductMessageDto message) {
log.info("이벤트 상품 요청 처리 memberId: {}, eventProductId: {}", message.getMemberId(), message.getEventProductId());
orderService.createOrder(message);
}
@RabbitListener에 Queue 이름을 넣어주면 메시지를 받을 수 있다.
받은 메세지를 이용하여 주문을 만드는 간단한 로직이다.
이제 동시성 테스트를 해보자.
@Test
void 비동기_이벤트_상품_동시성_테스트() throws Exception {
int numberOfThreads = 1000;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
for (int i = 0; i < numberOfThreads; i++) {
executorService.submit(() -> {
try {
member = memberRepository.save(createMember());
OrderDto.EventOrderRequest req = createOrderRequest(event.getId(), member.getId());
asyncService.processEventProduct(req, eventProduct.getId(), LocalDateTime.now());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
latch.countDown();
}
});
}
latch.await();
Thread.sleep(10000);
assertEquals(500, orderRepository.countOrderByEventAndProduct(event, product));
}
스레드 1000개를 이용하여 이벤트 상품 요청을 보내게 했다. 이때 RabbitMQ에서 메세지를 받아 처리하는 과정에서 시간이 걸리므로 10초 정도 뒤에 데이터 정합성 체크를 진행했다.
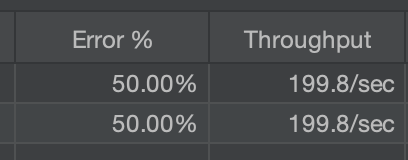
1000건을 요청했을 때 500건만 Queue에 들어가고 나머지 500건은 재고 없음으로 오류가 나므로 에러율이 50%가 잘 나오는 것을 볼 수 있다. 또한 Throughput 또한 분산락을 사용했을 때 비해 10배 이상 커진 것을 볼 수 있다.
여기서 성능이 급격하게 상승한 이유는 Lock을 사용하지 않았기 때문이다.
그러면 실제로 이벤트 상품의 재고를 DB에 업데이트를 할 때는 Lock을 사용하지 않으려고 스케줄링을 사용한다.
@Scheduled(fixedDelay = 10000)
private void updateEventProductQuantity() {
log.info("이벤트 상품 재고 동기화");
updateEventProductService.synchronizedQuantity();
}
10초마다 이벤트 상품의 재고를 동기화하는 코드이다.
정리하자면, 이벤트 상품의 요청이 들어오면 요청들은 Message Queue에 적재시킨다. 이때 Redis를 이용하여 이벤트 상품의 개수를 측정하고 있는다. (increment를 통해) 이를 통해 race condition을 방지할 수 있다.
그리고 스케줄러가 10초마다 이벤트 상품의 재고를 동기화시켜준다. (실제 DB에 재고 수를 반영)
스케줄러가 10초마다 동작하기 때문에 실제 주문이 입력되는 시점과 재고가 동기화되는 시점의 차이가 발생할 순 있지만 성능은 비약적으로 상승시킬 수 있다. 또한 Redis의 캐시를 이용하기 때문에 처음 조회할 때는 제외하고 DB에 접근할 일이 없기 때문에 DB의 접근을 최소화시킬 수 있다. Transaction의 범위 또한 재고를 동기화시켜주는 코드에서만 사용하면 되므로 이전에 비해 범위를 크게 줄일 수 있다.
Redis&Kafka를 활용한 선착순 쿠폰 이벤트 개발기 (feat. 네고왕)